![]()
![]()
![]()
![]()
Relacje (N, M)
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Relacje (N, M)
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Relacje (N, M)
![]()
![]()
![]()
![]()
W szerokim znaczeniu:
Baza danych. Zorganizowany zbiór informacji, zawierający jednolity rodzaj
danych.
W węższym znaczeniu
Baza danych (ang. data base). Zbiór uporządkowanych, powiązanych ze sobą
tematycznie danych zapisanych w pamięci komputera
Każda BD jest złożona z elementów o określonej strukturze: rekordów lub obiektów.
Z BD związane są z nią mechanizmy zarządzania, określające m. in. zasady porządkowania, wyszukiwania, edycji i modyfikacji
Potocznie bazą danych określa się także oprogramowanie do tworzenia i zarządzania bazami danych
Źródło: na podst. A. Rydzewski: Ilustrowany słownik techniki komputerowej, Warszawa 1995
Definicja techniczna:
Baza danych to zestaw związanych ze sobą obiektów (tablic,
formularzy, raportów, kwerend i zbiorów poleceń) utworzonych i
zorganizowanych przez system zarządzania bazą danych (database manegement
system - DBMS)
Zatem baza danych to:
DBMS (system zarządzania bazą danych)
Database manegement system [DBMS] (system zarządzania bazą danych - oprogramowanie użytkowe, które steruje danymi w bazie danych. Oprogramowanie to zajmuje się m. in.: organizacją, przechowywaniem, odzyskiwaniem, ochroną i nadzorem nad integralnością danych. DBMS może także: formatować raporty, importować i eksportować dane, a także dzięki własnemu językowi skryptów formułować zapytania (query)
Źródło: P. Dyson: Leksykon komputerowy. Warszawa 1994
Definicja prawna:
Baza danych oznacza zbiór danych lub jakichkolwiek innych materiałów i
elementów zgromadzonych według określonej systematyki lub metody,
indywidualnie dostępnych w jakikolwiek sposób, w tym środkami
elektronicznymi, wymagający istotnego, co do jakości lub ilości, nakładu
inwestycyjnego w celu sporządzenia, weryfikacji lub prezentacji jego zawartości
Źródło: USTAWA z dnia 27 lipca 2001 r. o ochronie baz danych // Dz.U. z 2001 r. Nr 128, poz. 1402. - Toż tryb dostępu: http://ks.sejm.gov.pl:8009/proc3/ustawy/3121_u.htm
Rekord (zapis) podstawowa jednostka informacji z bazie danych zawierająca pełny zestaw informacji o gromadzonych obiektach (np. opis bibliograficzny, dane teleadresowe itp.)
Wyróżniamy dwa podstawowe typy rekordów:
| Pola | ||||||||||
|
Autor |
Tytuł |
Podtytuł |
Miasto |
Rok |
…… |
|||||
| Rekordy |
Kowalski, Jan |
Poezje |
Warszawa |
2001 |
||||||
| Kowalski, Jan | Wspomnienia | Wrocław | 2001 | |||||||
| Wysocka, Ewa | Wspomnienia | młodość | Wrocław | 1999 | ||||||
Przykładowy rekord:
|
Hasło |
Strefa 1 |
Strefa 2 |
Strefa 4 |
||||||||||||
|
|
|
|
||||||||||||
Lub
|
Hasło |
Nazwisko |
Kowalski |
Imię |
Jan |
Data |
(1945-1998) |
|
Strefa 1 |
Tytuł |
Poezje |
Podtyt. |
|||
|
Strefa 2 |
Wyd. |
Wyd. 3 |
Równol. |
|||
|
Strefa 4 |
Miejsce |
Warszawa |
Wydawca |
PIW |
Rok |
2001 |
Przykład bazy kartotekowej
|
Rekord 1 |
Rekord 2 |
Rekord 3 |
|
N: Kowalski, Jan |
N: Kowalski, Jan |
N: Wysocka, Ewa |
Przykład bazy relacyjnej
|
|
||||||||||||||||||
|
Relacje (N, M)
|
Relacje (N, M)
|
Relacje (N, M)
|
|
|
|
... szerzej: Bazy danych. Ppodstawy relacyjnych baz danych. - http://db.tigra-system.pl/art.php?id=17
bazy rozproszone - posadowione na równych serwerach lub systemach (łączy je wspólny interfejs, zaś komunikacje umożliwiają sterowniki ODBC i język zapytań np. SQL, lub protokół Z39.50), np. KaRo: http://karo.umk.pl/
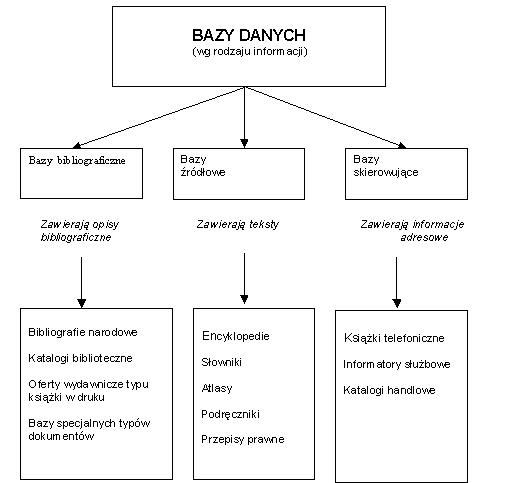
bibliograficzne, np.
źródłowe (faktograficzne), np.
skierowujące
|
|
|
Źródło: Sadowska J.: Jakie bazy danych w bibliotekach ? Por. Bibl. 2000 nr 6 s. 6-8 |
Relacyjne bazy danych (RDBMS)
Obiektowe bazy danych (ODBMS)
Obiektowo-relacyjne bazy danych (ORDBMS)
... szerzej: Bazy danych. Porównanie Relacyjnych, Obiektowych i Obiektowo-Relacyjnych Baz Danych. - http://db.tigra-system.pl/art.php?id=17
ze względu na zakres tematyczny danych
jednodziedzinowe
wielodziedzinowe
ze względu na zakres realizacji funkcji wyszukiwawczej w charakterystykach wyszukiwawczych dokumentów:
pełnotekstowe, zawierające teksty dokumentów pierwotnych
bibliograficzne, w których możliwe jest realizowanie funkcji wyszukiwawczej w pełnym zakresie charakterystyki wyszukiwawczej dokumentu.
(Tekst 1.4 wg: Włodzisław Duch, Notatki do wykładów wstępnych:
http://www.phys.uni.torun.pl/~duch/Wyklady/komput/spdypl.html)
1.5 Mechanizmy wyszukiwawcze:
|
Rekord 1 |
Rekord 2 |
Rekord 3 |
|
N: Adamski, Józef |
N: Kowalski, Jan |
N: Wysocka, Ewa |
|
|
|
Indeks aut: |
Indeks miejsc: |
|
|
Adamski, Józef |
Kraków |
Zaimplementowany w większości profesjonalnych DBMSach np. Oracje, DB2, Sybase, Accessie, czy MySQL. W przypadku Accessa język ów jest raczej rzadko wykorzystywany bezpośrednio do pracy w konsoli. Zwykle pośrednikiem pomiędzy SQL a użytkownikiem są kwerendy, makra itp. SQL umożliwia łatwą współpracę różnych baz danych i wykorzystanie ich w systemach internetowych i rozproszonych.
Definicja: Struktured query language [SQL] (strukturalny język zapytań) - w relacyjnych DBMS język zapytań wynaleziony przez IBM dla użycia na dużych komputerach. Został no też zaadaptowany przez Oracle Corporation do zastosowania na inne platformy (w tym PC). SQL jest obecnie standardem w większości profesjonalnych DBMS, szczególnie opartych na architekturze klient-serwer … SQL zawiera ok. 60 poleceńi jest używany do tworzenia i modyfikacji zapytań o raz sterowania dostępem do danych zorganizowanych w tablicach. SQL może być używany zarówno jako interfejs interaktywny, jak również jako wbudowane polecenia w programie aplikacji [na podst. P. Dyson: Leksykon komputerowy. Warszawa 1994)
1. Raporty - czyli wydruki
2. Formularze (Access), maski (MAK) - interfejsy ekranowe (inaczej: sposoby prezentacji danych)
3. Makra (skrypty) - miniprogramy wspomagające wykonywanie szeregu kolejnych czynności (np. sterowanie formularzami)
4. Moduły (fragmenty kodu źródłowego w języku programowania wysokiego poziomu, np. Visual Basic, C++ itp.) - moduły pełnią tę samą funkcje co marka. Są stosowane do projektowania skomplikowanych operacji. Np. obliczeń, skalowania, interakcyjnych interfejsów itp.
5. Mechanizmy grupowej modyfikacji (np. kwerendy aktualizujące w Accesie, czy procedury MAKa)
6. Strony dostępu (formularze umożliwiające dostęp przez www, Access 2000 i nowsze)
(Wyżej wymienione pojęcia są wspólne dla wszystkich baz danych!!!)
Zależnie od rodzaju danych jakie będziemy gromadzić w określonym polu. W bazie możliwe jest określenie różnych typów danych (wybrane)
Tekst (pozwala na wpisanie do pola maksymalnie 255 znaków) - (1 B)
Memo/nota (65,535 znaków), ale zajmuje dużo pamięci !!! (16 B)
Liczba (konieczne wtedy, gdy chcemy dokonywać obliczenia na danym polu) (1,2,4,8 lub 16 B)
Data/Godzina (8 B)
Waluta (8 B)
Autonuemer (4 lub 16 B)
Tak/Nie (1 B) (tzw. „ptaszek”)
Obiekt Ole (umożliwia dołączanie do bazy obiektów multimedialnych i różnych plików, np. muzyką, rysunki, filmy, dokumenty tekstowe, archiwa itp.) - do 1 GB
Hiperłącze (umożliwia aktywowanie danych jako link)
Lektura uzupełniająca:
Artykuł ze Słownika encyklopedycznego informacji, języków i systemów informacyjno-wyszukiwawczych. Oprac. B. Bojar. Warszawa 2002, s. 27-28
BAZA DANYCH - uporządkowany zbiór informacji (danych) z określonej dziedziny lub tematyki, przeznaczony do wyszukiwania. Termin baza danych upowszechnił się wraz z rozwojem informatyki, umożliwiającym tworzenie baz danych na maszynowym nośniku informacji. Obecnie oznacza zazwyczaj komputerową bazę danych. Ostatnio daje się zaobserwować tendencja zamiennego stosowania terminów baza danych i system informacyjny (system informacyjno-wyszukiwawczy). Często, zwłaszcza w literaturze z zakresu informatyki, terminem baza danych określany jest zbiór danych wraz z oprogramowaniem i innymi środkami służącymi do przetwarzania danych. Baza danych składa się z wielu zbiorów (plików), z których najważniejszymi są zbiór główny i indeks (indeksy). Rekordy w bazie oraz pola w rekordach mogą być wzajemnie powiązane. Istnieje wiele modeli danych, ale w praktyce bardzo często przy projektowaniu baz danych stosowane są rozwiązania własne. Przez wiele lat rozróżniano trzy podstawowe modele struktury bazy: hierarchiczny, sieciowy i relacyjny, a w ostatniej dekadzie bardzo się rozpowszechnił model obiektowy. Zdefiniowanie bazy danych polega na określeniu: (l) formatu rekordu (i ew. powiązań między rekordami), (2) formatu (formularza wejściowego) wprowadzania informacji do bazy, (3) zasad tworzenia indeksu (indeksów), (4) formatu wyświetlania/wydruku. Podczas projektowania bazy danych należy określić zasady tworzenia zapytań informacyjnych kierowanych do bazy. Tworzenie i użytkowanie baz danych wymaga korzystania z oprogramowania. Pakiety programów do obsługi baz danych są obecnie bardzo zróżnicowane, najogólniej należy rozróżniać oprogramowanie wewnętrzne, składające się na system zarządzania bazą danych, oraz oprogramowanie zewnętrzne, służące do realizacji konkretnej bazy danych. Baza danych może się fizycznie znajdować: (l) u dysponenta (producenta i/lub dystrybutora) bazy, użytkownik korzysta z bazy online za pośrednictwem sieci komputerowych lub zleca przeprowadzenie wyszukiwania w trybie wsadowym, (2) u użytkownika, który pozyskuje bazę na nośniku informacji (CD-ROM, taśma magnetyczna, dyskietka) do własnego przetwarzania: na jednym komputerze, na kilku komputerach lub w sieci lokalnej. Rozpowszechnia się także korzystanie z rozproszonych baz danych w modelu klient/serwer. Zaproponowano wiele typologii baz danych. Wyróżnia się rodzaje baz danych najczęściej zależnie od: a) Rodzaju gromadzonej w nich informacji: bibliograficzne, zawierające informację dokumentacyjną, i faktograficzne, zawierające informację faktograficzną; b) Rodzaju denotacji utrwalonych danych: źródłowe, denotujące obiekty rzeczywistości poza językowej, np. bazy danych faktograficzne i bazy danych odsyłające, denotujące zbiory dokumentów, czyli pełniące funkcję metainformacyjną względem innych zbiorów informacji. Bazę danych odsyłającą może stanowić baza danych bibliograficznych lub faktograficznych, np. baza danych terminologicznych (słownikowa) zawierająca terminologię danej dziedziny wiedzy lub słownik języka informacyjno-wyszukiwawczego, służąca jako pomoc przy formułowaniu strategii wyszukiwawczej, np. baza danych Chemname, Vocabulary Switching System (VSS). Bazy danych faktograficznych odsyłające do innych baz nazywane są często bazami skierowującymi, np. Dialindex w systemie Lockheed-Dialog; c) Zakresu tematycznego (pola semantycznego) danych: jednodziedzinowe i wielodziedzinowe. Wśród baz wielodziedzinowych wyróżnia się bazy transdyscyplinowe zawierające dane jednej głównej dziedziny, np. medycyny oraz w ograniczonym zakresie dane z innych dziedzin komplementarnych z punktu widzenia przedmiotu i metod badań, np. chemii, biologii; d) Rodzaju bazy notacyjnej danych: numeryczne, tekstowo-numeryczne i ikonograficzne; e) Poziomu opisu organizacji danych na nośniku informacji: logiczne, reprezentujące przyjęty w danym systemie informacyjno-wyszukiwawczym model danych oraz fizyczne, reprezentujące realizację danego modelu na konkretnym nośniku informacji; f) Przyjętego modelu danych (struktury danych): hierarchiczne, sieciowe, relacyjne; g) Zakresu realizacji funkcji wyszukiwawczej w charakterystykach wyszukiwawczych dokumentów (2). Z tego punktu widzenia wydziela się bazy danych: pełnotekstowe, zawierające teksty dokumentów pierwotnych, odróżniane od baz danych bibliograficznych, w których możliwe jest realizowanie funkcji wyszukiwawczej w pełnym zakresie charakterystyki wyszukiwawczej dokumentu. Por. wyszukiwanie pełnotekstowe; h) Przeznaczenia, które może polegać na zaspokajaniu potrzeb informacyjnych określonej kategorii użytkowników. Wyróżnia się tzw. bazy ukierunkowane zadaniowo, np. baza danych NASA, IN1S, ERDA. Wszystkie stosowane w praktyce podziały baz danych nie są podziałami logicznymi, ponieważ do ich uzyskania zastosowano jednocześnie różne kryteria. Typowymi elementami opisu baz danych w katalogach baz danych są: nazwa; skrót nazwy; inne wersje nazwy i skrótu nazwy; producent (często z rozróżnieniem na producenta informacji i na producenta bazy, np. na dysku CD-ROM); źródła informacji zawartych w bazie; język; typ; zakres geograficzny; zakres czasowy; zakres przedmiotowy (tematyka, opis zawartości); odpowiedniki drukowane i/lub na nośnikach maszynowych; informatyczne wymagania użytkowania; ograniczenia licencyjne; oprogramowanie; producent oprogramowania; data pierwszego wydania; częstotliwość aktualizacji; aktualna wersja bazy; cena (np. prenumeraty na jedno stanowisko, na wiele stanowisk, w sieci, w serwisach online);
2. BAZA DANYCH. Hasło z Nowej encyklopedii powszechnej PWN. - Tryb dostępu: http://encyklopedia.pwn.pl/6376_1.html
BAZA DANYCH, inform. zbiór wzajemnie powiązanych danych wraz z oprogramowaniem umożliwiającym ich definiowanie, wykorzystywanie i modyfikowanie. Powiązane tematycznie dane są grupowane w jednostki zw. rekordami i zapamiętywane w plikach; rekord odpowiada na ogół pewnemu konkretnemu opisywanemu obiektowi (osobie, rzeczy, pojęciu), pliki zaś grupują rekordy o podobnej strukturze. Programy baz danych — wyszukujące lub zmieniające dane — zawierają wiedzę o strukturze plików i rekordów: fiz. (metoda zapisu w pamięci) i log. (interpretacja programisty). Struktura bazy danych zależy od celu jej stworzenia, tzn. od rodzaju zastosowań, do których będzie używana.
Zorganizowanie wielkiej liczby danych oraz efektywne zarządzanie nimi (przy łatwym dostępie dużej liczby użytkowników z różnych, często odległych miejsc) wymagało stworzenia specjalnego oprogramowania obsługującego bazy danych, zw. systemami zarządzania baz danych lub systemami baz danych. Należą one do najbardziej skomplikowanych rodzajów oprogramowania — mają zarówno cechy kompilatorów, jak i systemów operacyjnych. Systemy baz danych są używane w fabrykach, bankach, szpitalach, urzędach itp., gdzie na co dzień korzysta się z wielu danych. Sposób reprezentowania obiektów modelowanego świata oraz zachodzących między nimi związków zależy od przyjętego modelu danych. Najczęściej używanymi modelami danych były (chronologicznie): hierarchiczny, sieciowy i relacyjny. Ten tradycyjny podział traci jednak powoli na aktualności.
W latach 70. i 80. dominowały scentralizowane systemy baz danych, w których wszystkie dane były zarządzane przez jeden komputer. Ostatnio zaczęły powstawać systemy rozproszonych baz danych, tj. takie, w których dane są przechowywane w różnych, oddalonych od siebie komputerach; za pośrednictwem sieci komputerowej system steruje dostępem do tych danych.
Od systemów baz danych (scentralizowanych i rozproszonych) wymaga się zapewnienia m.in.: integralności (poprawności) danych, współbieżnej obsługi żądań dostępu do baz danych, zgłaszanych jednocześnie przez różnych użytkowników, kontroli dostępu do danych, możliwości odtworzenia bazy danych (np. jej stanu przed awarią sprzętu).
Do poł. lat 80. uporano się zasadniczo z problemami sprawnego zarządzania dużymi zbiorami danych, efektywnej realizacji żądań użytkowników, a także niezawodności oraz ochrony dużych baz danych. Wraz z rozwojem systemów baz danych wykształciły się nowe potrzeby ich użytkowników: 1) lepszego modelowania świata rzeczywistego (zwł. w przypadku obiektów o złożonej strukturze); 2) sprawnego zarządzania danymi niesformatowanymi, np. tekstami, obrazami, mapami, sygnałami dźwiękowymi itp.; 3) przechowywania wiedzy o modelowanym świecie nie tylko za pomocą faktów, ale i w postaci ogólnych reguł, a także dokonywania na ich podstawie wnioskowania. Bazy danych spełniające wymagania 1 i 2 zw. są obiektowymi (obiektowo zorientowanymi), a wymaganie 3 — dedukcyjnymi; dotychczasowe rozwiązania (1990) mają raczej charakter badawczy i prototypowy.
3. Wybrane artykuły z Wikipedii [wersja pol.]: http://pl.wikipedia.org/wiki/
Baza danych składa się z danych oraz programu komputerowego wyspecjalizowanego do gromadzenia i przetwarzania tych danych. Program taki (lub zestaw programów) nazywany jest "Systemem zarządzania bazą danych" - z angielskiego Database management system. (Ponieważ "system zarządzania bazą danych" jest niewygodny w użyciu, to często samo oprogramowanie nazywa się również "bazą danych").
Bazy danych operują głównie na danych tekstowych i liczbowych, lecz większość współczesnych baz umożliwia przechowywanie danych binarnych typu: grafika, muzyka itp.
Bazy danych można podzielić według struktur danych których używają:
Podstawowe funkcje bazy danych to:
SQL to skrót od Structured Query Language (ang. strukturalny język zapytań). Jest to język programowania opracowany w latach siedemdziesiątych w firmie IBM. Stał się on standardem w komunikacji z serwerami relacyjnych baz danych, takimi jak IBM-owskie DB2 i SQL/DS, a także MySQL, PostgreSQL, Oracle, Microsoft SQL Server, Microsoft Access, Sybase Adaptive Server Enterprise, Sybase SQL Anywhere, Computer Associates Ingres, Informix, mSQL, First SQL i inne. Można powiedzieć, że korzystanie z relacyjnych baz danych, to korzystanie z SQLa. Pierwszą firmą, która włączyła SQL do swojego produktu komercyjnego, był Oracle. Dalsze wprowadzanie SQLa, w produktach innych firm, wiązało się nierozłącznie z wprowadzaniem modyfikacji pierwotnego języka. Wkrótce utrzymanie dalszej jednolitości języka wymagało wprowadzenia standardu.
W 1986 roku SQL stał się oficjalnym standardem, wspieranym przez Międzynarodową Organizację Normalizacyjną (ISO) i jej członka, Amerykański Narodowy Instytut Normalizacji (ANSI). Wczesne wersje specyfikacji (SQL86 i SQL89) były w dużej mierze jedynie określeniem wspólnej płaszczyzny łączącej różne istniejące wówczas produkty i pozostawiały wiele swobody twórcom implementacji. Z czasem jednak systemy komputerowe uległy integracji i rynek zaczął domagać się aplikacji oraz ich funkcji faktycznie współpracujących z wieloma różnymi bazami danych. Pojawiła się potrzeba określenia standardu ściślejszego. Mógł on jedynocześnie obejmować nowe elementy, nieujęte do tej pory w języku. Tak powstał SQL92, obowiązujący w produktach komercyjnych do dziś.
Produkty związane z relacyjnymi bazami danych to nie tylko serwery. Sam serwer określa się często takimi nazwami jak "back end", "engine", czy też "motor bazy danych". Przechowuje on dane oraz zapewnia ich pobieranie i aktualizacje w odpowiedzi na pobierane intstrukcje w SQLu.
Uzupełnieniem serwera jest zazwyczaj "front end", "middleware" czy też "fronton" - narzędzia upraszczające komunikację z serwerem i wyposażone w mechanizmy pozwalające wykorzystać pobrane dane. Należą do nich mechanizmy generowania i obsługi formularzy oraz raportów, języki czwartej generacji (4GL), graficzne języki zapytań, narzędzia konstrukcyjne użytkownika, oprogramowanie do prezentacji multimedialnych, systemy tworzenia hipertekstu, systemy CAD/CAM, arkusze kalkulacyjne, jak również interfejsy dostępu bezpośredniego. Wszystkie one wykorzystują, do komunikacji z serwerem i wykonywania za jego pośrednictwem różnych operacji, język SQL. Serwer odpowiada za przechowywanie, porządkowanie i pobieranie danych, zapewnia ich integralność, bezpieczeństwo oraz zabezpiecza przed ewentualnymi konfliktami między użytkownikami.
Z technicznego punktu widzenia, SQL jest podjęzykiem danych. Oznacza to, że jest on wykorzystywany wyłącznie do komunikacji z bazą danych. Nie posiada on cech pozwalających na tworzenie kompletnych programów. Jego wykorzystanie może być trojakie i z tego względu wyróżnia się trzy formy SQLa:
Wymagania tych trzech form różnią się i znajduje to odbicie w wykorzystywanych przez nie konstrukcjach językowych. Zarówno statyczny, jak i dynamiczny SQL uzupełniają formę autonomiczną cechami odpowiednimi tylko w określonych sytuacjach. Większość języka pozostaje jednak dla wszystkich form identyczna.
4. Wybrane artykuły z Wielkiej internetowej encyklopedii multimedialnej WIEM: http://wiem.onet.pl/
Przez integralność bazy danych rozumie się wierne odzwierciedlanie przez nią przedmiotu zainteresowania jej użytkowników. Prostymi przykładami baz danych są spisy towarów, rozkłady jazdy, ewidencje pracowników, wykazy płatnicze, wszelkiego rodzaju rejestry bankowe, kartoteki urzędowe, biblioteki, katalogi, książki telefoniczne, szpitalne historie chorób, dzienniki lekcyjne, wykazy osób podejrzanych, księgi parafialne itd. Wszystkie one muszą spełniać jeden warunek: ich tworzenie, przechowywanie, uaktualnianie i przeszukiwanie powinno się odbywać w komputerze.
Najprostsze bazy danych są jednopoziomowe (płaskie) i są tworzone przez plik jednostek o jednolitej strukturze, zwanych rekordami. Rekordy, czyli elementy składowe pliku bazy danych, zawierają pola różnorodnych typów: numeryczne, znakowe, tekstowe, pola walut, a w przypadku baz multimedialnych także pola wskaźnikowe odnoszące się do zapamiętanych w komputerze cyfrowych obrazów, animacji i dźwięków. W zależności od charakteru przedmiotu zainteresowania bazy danych tworzą wielokolumnowe tabele spełniające ścisłe wymogi. Tabele takie określa się mianem relacji, a tworzone przez nie bazy nazywa się relacyjnymi bazami danych. W zarządzaniu informacją baz danych są przydatne klucze, za pomocą których określa się zapytanie kierowane do baz danych lub reguły porządkowania baz danych (sporządzanie indeksów baz danych). Istnieją standardowe języki obsługi baz danych, np. SQL. Praktycznie nie ma już dziedziny zainteresowań, która nie podlegałaby odwzorowaniu w komputerową bazę danych. Dysponowanie właściwą informacją o określonym obiekcie w określonym czasie i miejscu jest zawsze cenną wartością, pomocną w podejmowaniu udanych decyzji.
Hasło opracowano na podstawie “Słownika Encyklopedycznego - Informatyka” Wydawnictwa Europa. Autor - Zdzisław Płoski. ISBN 83-87977-16-0. Rok wydania 1999.
Zobacz również
Plik, Rekord, Pole, Encja, Relacja, Klucz, Rozproszona baza danych
Hasło opracowano na podstawie “Słownika Encyklopedycznego - Informatyka” Wydawnictwa Europa. Autor - Zdzisław Płoski. ISBN 83-87977-16-0. Rok wydania 1999.
Hasło opracowano na podstawie “Słownika Encyklopedycznego - Informatyka” Wydawnictwa Europa. Autor - Zdzisław Płoski. ISBN 83-87977-16-0. Rok wydania 1999.
Hasło opracowano na podstawie “Słownika Encyklopedycznego - Informatyka” Wydawnictwa Europa. Autor - Zdzisław Płoski. ISBN 83-87977-16-0. Rok wydania 1999.
Więcej informacji [dla zaawansowanych]:
© W. M. Kolasa. Kraków 2003 http://www.wmkolasa.up.krakow.pl/ - ostatnia modyfikacja: