Wśród testowanych programów pojawiły się także trzy nowe, które dopiero wkraczają na rynek. Trudno orzec czy zdobędą popularność porównywalną z przedstawionymi wcześniej, gdyż w większości przypadków są obarczone jeszcze jakimiś wadami lub niedostatkami.
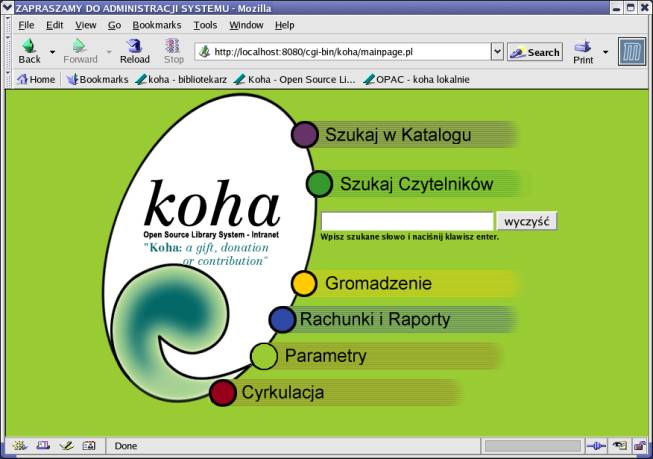
KOHA. Profesjonalny, bezpłatny program biblioteczny rozpowszechniany na licencji GNU GPL rozwijany przez woluntariuszy z całego świata (nad polską wersją pracują Benedykt Barszcz i Paweł Skuza). System powstał w Nowej Zelandii i jest użytkowany m. in. we Francji. Zainteresowani mogą zapoznać się z obszerną polską i angielską dokumentacją na stronach EBIB-u[7] lub na stronach Studio of Arts And Sciences[8]. Sporym atutem programu jest to, że działa zarówno w systemie Windows (wersja częściowo spolszczona), jak i na Linuksie (ostatnia wersja – 2.0.1RC1, spolszczona w 95%). Do pracy wymaga jedynie przeglądarki internetowej, zaś na serwerze kilku darmowych komponentów (serwer www Appache, baza danych MySQL i język Perl oraz skrypty systemu KOHA). Zupełnie za darmo otrzymujemy siedem w pełni funkcjonalnych modułów (OPAC, udostępnienie, czytelnicy, gromadzenie i katalogowanie, raporty, ustawienia i administracja). System KOHA ma szereg niewątpliwych zalet: jest bezpłatny, obsługuje standardy (MARC21, z39.50, SQL), zapewnia kontrolę wzorcową wybranych pól, daje możliwość pracy z kodami kreskowymi, jest skalowalny, ma duże możliwości konfiguracyjne i jest w dużym stopniu spolszczony. Jednak w obecnej formie trudno polecić go bibliotekom, gdyż wymaga szeregu czynności adaptacyjnych, które trzeba jeszcze wykonać.
Rys 6. KOHA – panel główny
Aktualne problemy to przede wszystkim brak przetestowanej bazy wzorcowej odpowiedniej dla polskiej specyfiki. Należy zatem zdefiniować odpowiedni wykaz pól MARC21 (np. taki, jak w NUKAT), obecnie wzorem jest Library of Congress, dopracować kodowanie, konwertery (np. ISO), dokończyć klienta z39.50 do współpracy z NUKAT-em i INNOPAC BN (jest to już częściowo wykonane), zdefiniować odpowiednie statystyki i wzory druków, wraz z możliwością eksportu do PDF i RTF. Brak też w obecnej formie wydzielonych tablic z kontrolą khw (pola: 1xx, 440, 6xx, 7xx, 8xx), brak helpów, niekompletne jest tłumaczenie części interfejsu. Wielce pożądanym byłoby także zdefiniowanie podbazę dla bibliografii regionalnej, opracować polski podręcznik dla bibliotekarza, polski opis instalacji i konfiguracji oraz łatwy program instalacyjny (np. „gotowiec” typu „Krasnal”)
MINILIB. System wrocławskiej formy Mikram[9], rozwijany od 1996 r. (26 instalacji). Znamienną jego cechą jest niemal lustrzane funkcjonalnie podobieństwo do Prolib-a (jakby miniProlib), o czym zresztą informuje producent, zapewniając, że jest on w pełni zgodny z PROLIB-em. W całości działa w architekturze klient-serwer (baza Interbase/Firebird) w graficznym środowisku Windows. Użytkownicy otrzymują dziewięć modułów: katalogowanie wydawnictw zwartych, katalogowanie wydawnictw ciągłych, wypożyczalnia, zestawienia (statystyki, wydruki, inwentarze), moduł eksportu/importu (MARC21, MARCBN), OPAC, OPAC WWW[10] i moduł administracyjny. Program w obecnej formie ma jednak pewne braki: dużo do życzenia pozostawia ergonomia - zbyt wiele operacji potrzebnych do wykonania prostych czynności (tę samą wadę ma Prolib), brak klienta z39.50, niepotrzebnie autoryzowane są różne pola (np. podtytuły), moduł OPAC jest zbyt skomplikowany i mało funkcjonalny, a w module katalogowym występuje kilka błędów (istotnych dla obsługi MARC).
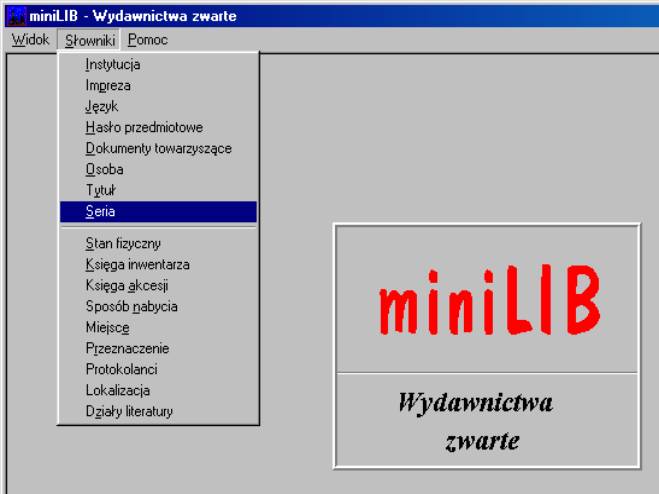
Rys. 7. MiniLIB – moduł wydawnictw zawartych i panel podstawowy
MATEUSZ. Program autorstwa Mirosława Domańskiego, którego główną funkcją jest obsługa wypożyczeń w placówkach o rozproszonych strukturach. Od kilku lat rozwijany i użytkowany w sieci Biblioteki Publicznej Warszawa–Bemowo (planowany do rozpowszechniania na licencji freeware). Działa w architekturze klient-serwer (dowolny serwer SQL, Windows, Linux) w graficznym środowisku Windows[11] (klient). Użytkownik programu otrzymuje cztery podstawowe moduły: udostępnianie centralne (transakcje, rezerwacja, prolongaty, monity, kary itp.), statystyki, wydruki, raporty (wszystkie potrzebne w bibliotece publicznej), obsługa czytelni (rejestracja czynności, statystyki), kontrola dostępu do internetu na stanowiskach czytelników i OPAC WWW[12] oraz – co ważne – dobrze dopracowany, intuicyjny podręcznik dla bibliotekarza. System w obecnej formie ma jednak podstawową wadę - nie ma własnego modułu katalogowania. Po uprzedniej konwersji korzysta z baz innych systemów np. MAK (autor dopiero niedawno podjął prace nad samodzielnym modułem katalogowania).
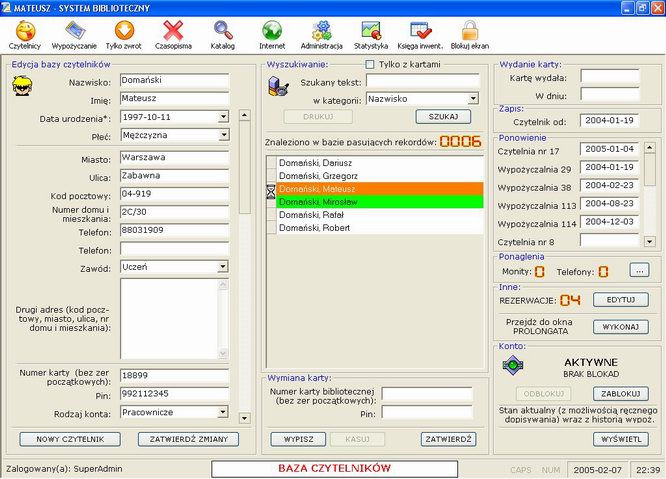
Rys. 8. Mateusz – moduł wypożyczeń
-------------------------------------------------
[7]
Zob. http://ebib.oss.wroc.pl/techno/index.php?koha.
[8]
Zob. http://www.saas.nsw.edu.au/.
[9]
Zob. http://www.mikram.com.pl, tamże
opis systemu i do pobrania wersja demonstracyjna.
[10]
Zob. np. http://156.17.106.101.
[11]
Obszerny opis na stronie: http://www.e-bp.pl/makowe.php
[12]
Np. http://www.biblioteka.isg.pl
© W. M. Kolasa. Kraków 2005 http://www.wmkolasa.up.krakow.pl [aktualizacja: 2005.01.26]